2 · Predicted-Flow CBFs
From the Current State to the Predicted Flow
Let \(T > 0\) be the planning-and-prediction horizon, and consider the
control plan \(u_{\rm p}(\,\cdot\,;\theta) \colon [0, T] \to \mathbb{R}^m\),
which is parametrized by \(\theta \in \mathbb{R}^d\).
The control plan \(u_{\rm p}\) is continuous on \([0,T] \times \mathbb{R}^d\),
and for all \(\tau \in [0,T]\), \(u_{\rm p}(\tau;\,\cdot\,)\) is continuously
differentiable on \(\mathbb{R}^d\).
Let \(k \colon \mathbb{R}^d \to \mathbb{R}\) be continuously differentiable, and define
the admissible parameter set
\[
\Theta \triangleq \{\theta \in \mathbb{R}^d : k(\theta) \geq 0\},
\]
where for all \((\tau,\theta) \in [0,T] \times \Theta\),
\(u_{\rm p}(\tau;\theta) \in \mathcal{U}\).
In order to influence the time evolution of \(\theta\), let
\(\theta \colon [0, \infty) \to \mathbb{R}^d\) be the solution to
\[
\dot\theta(t) = \omega(t), \qquad \omega(t) \in \Omega \subseteq \mathbb{R}^d,
\label{eq:theta} \tag{5}
\]
where \(\theta(0) = \theta_0 \in \mathbb{R}^d\) and \(\omega\) is the control input
to the integrator.
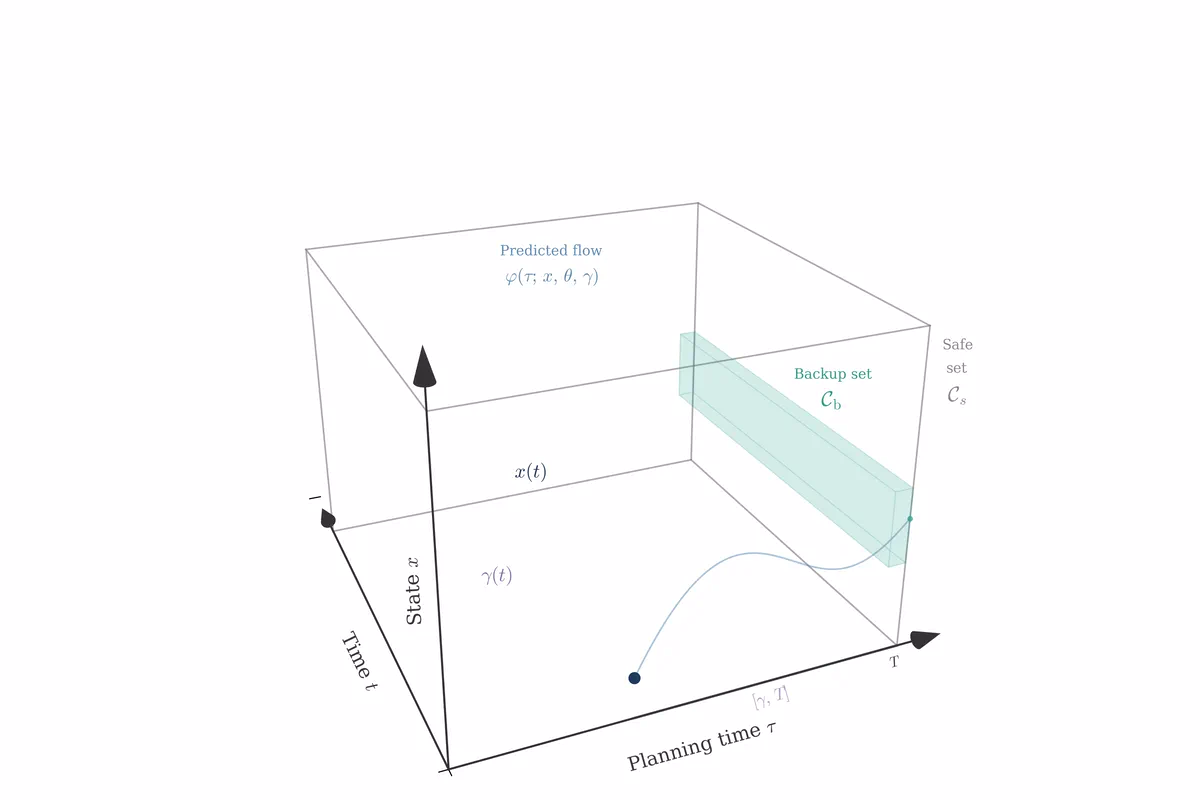
The predicted flow \(\phi(\,\cdot\,; x, \theta) \colon [0, T] \to
\mathbb{R}^n\) satisfies
\[
\phi(\tau; x, \theta) = x + \int_0^\tau
F\!\bigl(\phi(\sigma; x, \theta),\, u_{\rm p}(\sigma; \theta)\bigr) \, d\sigma.
\label{eq:flow} \tag{6}
\]
which implies that \(\phi(\tau; x, \theta)\) is the solution to \eqref{eq:sys}
at planning time \(\tau \in [0,T]\) with initial condition \(x\) and
\(u = u_{\rm p}(\,\cdot\,;\theta)\).
In other words, \(\phi(\,\cdot\,; x, \theta)\) is the flow of \eqref{eq:sys} from
state \(x\) under the plan \(u_{\rm p}(\,\cdot\,;\theta)\) with parameter \(\theta\).
Next, let \(H_1, \ldots, H_\ell \colon C([0,T], \mathbb{R}^n) \to \mathbb{R}\) be
functionals such that for all \(i \in \{1, \ldots, \ell\}\),
\[
\psi_i(x, \theta) \;\triangleq\; H_i\bigl[\phi(\,\cdot\,; x, \theta)\bigr]
\label{eq:psi} \tag{7}
\]
is locally Lipschitz and directionally differentiable on
\[
\Psi \;\triangleq\; \bigl\{(x,\theta) \in \mathbb{R}^n \times \mathbb{R}^d
: k(\theta) \geq 0,\; \psi_1(x,\theta) \geq 0, \ldots, \psi_\ell(x,\theta) \geq 0\bigr\}.
\label{eq:Psi-def} \tag{8}
\]
Note that \(\Psi\) is the set of \((x, \theta)\) such that the predicted flow
\(\phi\) mapped through each functional \(H_i\) is nonnegative, and
\(\theta \in \Theta\), which implies that \(u_{\rm p}(\tau;\theta) \in \mathcal{U}\)
for the entire planning horizon \(\tau \in [0, T]\).
We now introduce the concept of a predicted-flow CBF.
This concept extends the notion of a D-CBF to address the \(\ell\)-tuple
\((\psi_1, \ldots, \psi_\ell)\), where each \(\psi_i\) is obtained by mapping
\(\phi\) through the functional \(H_i\) and where \(k\) defines the admissible
parameters for the control plan.
Definition 4
(Predicted-Flow CBF)
Assume \(\psi_1, \ldots, \psi_\ell\) given by \eqref{eq:psi} are locally Lipschitz
and directionally differentiable on \(\Psi\).
Then, \((\psi_1, \ldots, \psi_\ell)\) is a predicted-flow control barrier
function (P-CBF) \(\ell\)-tuple for \eqref{eq:sys} and \eqref{eq:theta} on
\(\Psi\) given \(u_{\rm p}\) and \(k\) if there exist extended
class-\(\mathcal{K}\) functions
\(\alpha_1, \ldots, \alpha_\ell, \beta\) such that for all
\((x, \theta) \in \Psi\), \(K_\Psi(x, \theta)\) is nonempty, where
\(K_\Psi \colon \Psi \rightrightarrows \mathcal{U} \times \Omega\) is defined by
\[
K_\Psi(x, \theta) \;\triangleq\; \bigl\{\, (\hat u, \hat\omega) \in \mathcal{U} \times \Omega \,:\,
\begin{aligned}[t]
&\; k'(\theta)\,\hat\omega + \beta(k(\theta)) \geq 0, \\[2pt]
&\; D_{\left[\begin{smallmatrix} F(x,\hat u) \\ \hat\omega \end{smallmatrix}\right]}\, \psi_1(x, \theta) + \alpha_1(\psi_1(x,\theta)) \geq 0, \ldots, \\[2pt]
&\; D_{\left[\begin{smallmatrix} F(x,\hat u) \\ \hat\omega \end{smallmatrix}\right]}\, \psi_\ell(x, \theta) + \alpha_\ell(\psi_\ell(x,\theta)) \geq 0 \,\bigr\}.
\end{aligned}
\]
Theorem 2
(P-CBF Forward Invariance)
Assume \((\psi_1, \ldots, \psi_\ell)\) is a P-CBF \(\ell\)-tuple for \eqref{eq:sys}
and \eqref{eq:theta} on \(\Psi\), and let
\(u_{\rm fi} \colon \Psi \to \mathcal{U}\) and \(\omega_{\rm fi} \colon \Psi \to \Omega\)
be such that for all \((x,\theta) \in \Psi\),
\((u_{\rm fi}(x,\theta), \omega_{\rm fi}(x,\theta)) \in K_\Psi(x,\theta)\).
Then, \(\Psi\) is forward invariant with respect to \eqref{eq:sys} and \eqref{eq:theta}
with \((u, \omega) = (u_{\rm fi}, \omega_{\rm fi})\).